迷你課程:R語言-13~數據資料再訪

Quick look
這堂課程參考劍橋大學的課程 (Introduction to R for Biologists),主要會示範如何從原始 CSV 檔案下載、載入並檢查資料,以及如何操作 data.frame 結構,包括:索引、子集、類別變數(factor)處理等。強化資料探索的基本能力,為後續資料分析打下基礎
課程前置準備:下載資料
download.file(url = "https://ndownloader.figshare.com/files/2292169",
destfile = "data/portal_data_joined.csv")
這邊的url給的網址可以讓我們從fishare上下載檔案,而destfile是你需要設定的檔案下載位置。
檔案下載完成後,可在 RStudio 的 Files 面板中點開 data/portal_data_joined.csv 並檢視內容。
初步理解資料格式與欄位
從上述 portal_data_joined.csv 檔案的前四行可以看出,這是一個逗號分隔值(CSV, Comma Separated Values)格式的檔案。這種格式非常常見,用來儲存表格資料,其中每個值之間用逗號隔開。
檔案的第一行是標題列(header),它為每一欄提供了名稱或描述。這份資料集的研究對象是:在實驗地區的不同樣區(plot)中捕捉到的動物,其物種分布與體重。
此資料集中,每一列代表一隻動物的資訊,包含以下欄位:
- record_id: 觀測紀錄編號
- month, day, year: 日期資訊
- plot_id: 取樣地點編號
- species_id: 物種代碼
- sex: 性別(M / F)
- hindfoot_length: 後足長(mm)
- weight: 體重(g)
- genus, species: 屬與種名
- taxa: 類別(如 Rodent, Bird 等)
- plot_type: 地點類型(Control / …)
載入資料至 R:read.csv()
接者我們來把這個CSV檔讀取進來:
surveys <- read.csv("data/portal_data_joined.csv")
檢視前幾列:
head(surveys)
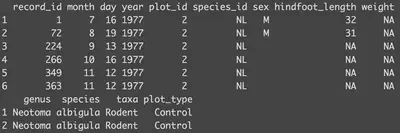
也可以使用:
View(surveys) # 開啟資料檢視器
read.csv 函數預設認為每一欄的資料是以逗號(,)分隔的。不過,在某些國家(例如法國、德國等),逗號常被用作小數點,因此他們習慣使用分號(;)來作為欄位分隔符號。
如果你要讀取這類使用分號作為欄位分隔的檔案,在 R 裡可以改用 read.csv2 函數。這個函數的用法和 read.csv 一樣,但它使用了不同的預設參數(小數點使用逗號、欄位分隔使用分號)。
如果你的資料格式與這些都不相同,你也可以自己指定欄位分隔符號(sep)和小數點符號(dec)。
你可以輸入 ?read.csv 來查看更多說明。
此外,如果你的資料是以Tab(製表符)作為欄位分隔的話,可以使用 read.delim() 函數來讀取。
這些函數其實都是 read.table() 函數的簡化包裝(wrapper functions),只是預先設定好了參數。例如,上述的 surveys 資料,也可以這樣載入:
surveys <- read.table(file="data/portal_data_joined.csv", sep=",", header=TRUE)
其中 header=TRUE 表示第一列是欄位名稱。這是必要的,因為 read.table() 的預設值是 header=FALSE,不會自動當成欄位名稱。
Data frames
在 R 語言中,資料框(data frame)是一種最常用、最重要的資料結構,因為現實生活中大多數資料都以表格(tabular)形式呈現。而在 R 裡,不論是畫圖還是統計分析,大多也都是以資料框作為輸入。
簡單來說,資料框就像是一個表格,每一欄是向量(vector),而所有欄位的長度必須相同。由於每欄是向量,因此每一欄裡的資料型態必須一致,例如:只能是字串(character)、整數(integer)或邏輯值(logical)等單一類型。
舉個例子,一個資料框可以包含:
- 第一欄是數字(numeric)
- 第二欄是文字(character)
- 第三欄是邏輯值(TRUE/FALSE) 這樣的結構就像一張資料表,每列代表一筆觀測值,每欄則是不同的變數。這讓 R 能夠有效處理和分析各種型態的資料。
檢視資料結構與摘要資訊
我們可以用str()來檢視資料框的結構:
str(surveys)
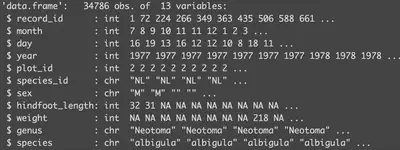
檢視 data.frame 物件的內容與結構
如同之前提到的,在進行資料分析前,先了解資料的結構與內容是非常重要的。此外,我們也必須確認資料是否已經正確地讀入 R 中。為了做到這些,我們可以使用幾個實用的函數來檢查和瀏覽 data.frame 物件。
我們已經看過 head()、View() 和str() 這些函數,它們能幫助我們快速查看資料表的內容與結構。下面列出更多常用的檢視函數,讓我們可以從不同角度理解資料。
尺寸資訊(Size)
dim(surveys):回傳一個向量,第1個元素是列數(rows),第2個是欄數(columns)。nrow(surveys):取得資料的列數。ncol(surveys):取得資料的欄數。
內容概覽(Content)
head(surveys):顯示前 6 筆資料。tail(surveys):顯示後 6 筆資料。
欄位與列名稱(Names)
names(surveys):回傳所有欄位名稱(等同於 colnames())。rownames(surveys):回傳所有列的名稱(預設通常是數字編號)。
結構與摘要(Summary)
str(surveys):查看資料的結構,包括每一欄的資料型別、長度及前幾筆內容。summary(surveys):針對每個欄位顯示簡單的統計摘要(例如最小值、最大值、平均數、缺失值數量等)。
補充說明
這些函數大多是泛型函數」(generic functions),不只能用於 data.frame,也可用於向量、清單(list)、矩陣等其他資料類型。學會這些函數,有助於你在分析前更快速、全面地掌握資料狀況。
數值索引(Numeric Indexing)
在 R 語言中,data frame 可以視為一個由列(rows)與欄(columns)組成的表格。 每一個元素的位置可透過「列與欄的編號」來定位,其語法格式為:[R, C],其中:
- R 表示第幾列(row number)
- C 表示第幾欄(column number) 請注意:
- 方括號 [] 用於索引(indexing)
- 小括號 () 用於呼叫函數(function call)
- R 語言的索引從 1 開始(不是 0) 若想要從一個名為 surveys 的資料框中擷取特定資料,就必須指定欲擷取資料的「列與欄的位置」。
# get first element in the first column of the data frame
surveys[1, 1]
# get first element in the 6th column
surveys[1, 6]
# get first column of the data frame (as a vector)
surveys[, 1]
# get first three elements in the 7th column (as a vector)
surveys[1:3, 7]
# get the 3rd row of the data frame (as a data.frame)
surveys[3, ]
# equivalent to head_surveys <- head(surveys)
head_surveys <- surveys[1:6, ]
: 是 R 中的一個運算子,用來產生遞增或遞減的整數序列
這個運算子會建立一個從某個整數開始、到某個整數結束的連續整數向量。
語法:起始值 : 結束值
舉例:
- 1:10 → 產生從 1 到 10 的整數序列
- 10:1 → 產生從 10 到 1 的倒序整數序列 這個寫法其實等價於函數 seq(from, to),例如:
1:10 # 結果為 1 2 3 4 5 6 7 8 9 10
seq(1, 10) # 相同結果
使用 - 可以從資料框中排除特定的列或欄
在索引中加入負號可以告訴 R不要選這個位置,例如:
surveys[-1, ] # 排除第1列(row)
surveys[, -2] # 排除第2欄(column)
這讓你能夠在不修改原始資料的情況下,快速排除不需要的部分。
也可以搭配 :使用,例如:
surveys[-(1:3), ] # 排除第1到第3列
名稱索引(Name indexing)
除了使用數字位置來提取資料,R 的資料框也可以透過欄位名稱或列名稱來進行索引,這種方式稱為名稱索引。以下是幾個常見的範例:
# 以向量形式取得 species_id 欄
surveys[, "species_id"]
# 同上,使用 $ 符號也能直接取得欄位
surveys$species_id
# 取得前 3 筆資料的 record_id 與 species 欄(混合數字與名稱索引)
surveys[1:3, c("record_id", "species")]
小技巧:在 RStudio 中,輸入 surveys$ 後會自動補齊欄位名稱,有助於避免拼錯。
邏輯索引(Logical indexing)
另一種強大且常用的資料擷取方式是邏輯索引,即利用邏輯條件從資料框中挑選出特定資料。
# 取得所有 species 欄為 "albigula" 的紀錄
surveys[surveys$species == "albigula",]
# 將這些紀錄儲存到 albigula_data 變數中
albigula_data <- surveys[surveys$species == "albigula",]
# 計算 albigula 的總筆數
nrow(albigula_data)
這種方式非常適合用來過濾資料,例如找出某物種的所有觀察記錄。
因子(Factors):處理分類資料的利器
當我們使用 str(surveys) 檢視資料框結構時,可以發現大多數欄位是整數類型(integer),但像是 genus、species、sex、plot_type 等欄位則是字元型別(character)。其實,這些欄位的資料是屬於分類變數``(categorical data),也就是只能取有限種類的值。
為什麼要用 Factor?
R 語言提供了一種專門處理分類資料的資料型別,叫做 factor。它非常適合處理類別型資料,也是 R 擅長資料處理的原因之一。
一個 factor 只能包含預先定義的等級(levels),而且可以是有順序的(ordered)或無順序的(unordered)。雖然看起來像字串,實際上 factor 是以整數方式儲存的,所以在當作文字處理時需要特別注意。
建立 factor
我們可以透過 factor() 函數,把分類資料轉成 factor 類型,例如:
surveys$sex <- factor(surveys$sex)
轉換完成後,用 summary() 來快速檢視各個 level 的數量:
summary(surveys$sex)
Factor 的預設順序
R 在處理 factor 時,預設會依照字母順序排列 levels。例如:
sex <- factor(c(“male”, “female”, “female”, “male”))
雖然第一個值是 “male”,R 還是會將 "female" 排在前面(因為 f < m),這可由下列方式確認:
levels(sex) # 顯示 levels 名稱
nlevels(sex) # 顯示 levels 數量
自訂 levels 順序
有時候你可能需要手動設定順序,例如資料是low, medium, high這種有意義的順序,或是為了改善圖像呈現,甚至是因為某些統計方法會考慮順序。
sex <- factor(sex, levels = c("male", "female"))
這樣就可以改變 level 的順序。
為何使用 factor 比單純的數字更好?
儘管 R 在內部是用數字(1, 2, 3, …)來儲存因子,但 factor 具備描述性,像 “female”、“male” 的表示比單純的 1、2 更直觀、更具可解釋性。
尤其當類別很多(像物種名稱)時,factor 就顯得格外有用,能幫助你更清楚地處理、呈現和分析分類資料。
因子轉換(Converting factors)
在某些情況下,我們需要將factor轉換為其他資料型別,如character或numeric:
轉為字元型別
要將因子轉為字元,可以使用 as.character():
as.character(sex)
這在你想要保留文字本身、而非 factor 結構時很有用。
轉為數值型別的常見陷阱
若因子本身看起來是數字(例如年份、濃度),直接使用 as.numeric() 會出錯,因為這個函數其實會回傳因子的等級編號(也就是內部編碼的順序),而不是你眼睛看到的數字!
year_fct <- factor(c(1990, 1983, 1977, 1998, 1990))
as.numeric(year_fct)
# 錯誤!會回傳 3 2 1 4 3 這類順序,而不是年份本身
正確轉換方式
有兩種推薦的方式:
方法 1:先轉為字串再轉為數字
as.numeric(as.character(year_fct))
方法 2:推薦使用 levels() 配合因子的編碼
as.numeric(levels(year_fct))[year_fct]
這方法可以分為三個步驟理解:
levels(year_fct)取得所有等級值(會是字串)as.numeric(levels(year_fct))將等級轉為數字- 用
year_fct當作索引來選取正確的數值
這樣就可以準確保留原始數值資訊,避免錯誤的轉換結果。
再看一個例子:
df <- data.frame(
a = c('A', 'B'),
b = c('1998', '2004')
)
df$a <- factor(df$a)
df$b <- factor(df$b)
as.numeric(df$b)
as.numeric(levels(df$b))[df$b)]
現在 df$b 是一個因子,裡面的值看起來像是 “1998”、“2004”,但底層實際上是整數索引:
levels(df$b)
# [1] "1998" "2004"
as.numeric(df$b)
# [1] 1 2 ← 實際儲存的索引位置
另外因為 df$b 是一個因子,當你把它用作向量索引時,R 會自動取出它的底層整數值(即因子的 level 編號),讓你用來選擇正確的位置。
因子重新命名(Renaming Factors)
當資料中的某個欄位是factor型態時,我們可以用 plot() 來快速檢視各個因子層級(levels)下的樣本數:
plot(surveys$sex)
問題:有約 1700 筆資料的性別是缺失(NA),因此不會出現在圖中。
解法:我們可以把這些缺失值轉為新的因子層級,並加上名稱:
sex <- as.factor(surveys$sex)
levels(sex)[1] <- "undetermined"
現在 plot 時會顯示 “undetermined” 分類。
stringsAsFactors=TRUE 的意義?
當你用 read.csv() 或 read.table() 讀取資料時,若設定 stringsAsFactors=TRUE,R 會自動把字串轉為因子。這可以避免不必要的文字比對錯誤,也能用於分群、繪圖等操作。
surveys <- read.csv("data/portal_data_joined.csv", stringsAsFactors = TRUE)
相反地,若你希望保留文字原貌,可以使用:
surveys <- read.csv("data/portal_data_joined.csv", stringsAsFactors = FALSE)
課程小結
本次介紹了 R 中處理表格資料的核心技能,從 read.csv() 讀取資料,到認識 data.frame 結構,再深入至數值、名稱與邏輯索引,最後拓展到處理分類變數(factor)與其轉換與重命名技巧。透過實作與範例,課程幫助學員建立資料探索與清理的基本觀念,為後續的統計分析與視覺化奠定紮實的基礎,特別適合剛入門資料分析與生物資訊的學習者。