迷你課程:R語言-11~dplyr

Quick look
dplyr 是 R 中最常用的資料處理套件之一,特別適合用於資料整理、過濾、轉換與摘要。在本課程中,我們使用 ggplot2 套件內建的 mpg 資料集,來進行一系列的實作練習。
library(dplyr)
library(ggplot2) # for the mpg dataset
# 載入內建的 mpg dataset
data(mpg)
dat <- mpg
head(dat)
這段程式碼載入 mpg 資料集並檢視前幾筆資料。mpg 包含美國市面上各種汽車的油耗、車種與引擎資訊。
資料結構觀察
class(dat)
glimpse(dat)
summary(dat)
- class():檢查資料的類型(通常是 data.frame 或 tibble)
- glimpse():快速檢視每一欄位的型別與部分內容
- summary():提供每個欄位的基本統計摘要(例如平均值、最大值)
這些工具有助於我們了解資料的內容與結構,是資料分析的第一步。
篩選資料:filter()
filter(dat, manufacturer == "toyota")
filter(dat, hwy > 30)
filter(dat, manufacturer == "toyota", hwy > 30)
filter() 用於根據條件篩選列(rows)。你可以依據某廠牌、油耗表現等篩選出感興趣的車款。多個條件會自動使用 AND 關係。
欄位選取:select()
select(dat, manufacturer, model, hwy)
select(dat, contains("cty"))
select(dat, starts_with("d"))
select(dat, where(is.numeric))
select() 用來選取欄位。可以指定欄位名稱、關鍵字或是使用 where() 搭配函數過濾型別(如數值欄位)。非常適合整理與精簡資料集。
資料排序:arrange()
arrange(dat, desc(hwy))
filter(dat, hwy > 30) |> arrange(hwy)
arrange() 可將資料依欄位數值做排序,預設為遞增,使用 desc() 則為遞減排序。搭配 filter() 可先選後排,或搭配 mutate() 做多欄位排序。
新增欄位:mutate()
mutate(dat, avg_mpg = (cty + hwy)/2)
mutate(dat, avg_mpg = (cty + hwy)/2) |> select(manufacturer, model, avg_mpg)
mutate() 可以新增計算欄位。例如計算平均油耗 (cty + hwy)/2,是做衍生變數與前處理的常見方式。
分組與摘要:group_by() + summarize()
mpg_summary <- dat |>
group_by(manufacturer) |>
summarize(avg_hwy = mean(hwy, na.rm = TRUE), count = n()) |>
arrange(desc(avg_hwy))
group_by() 先將資料按類別分組,然後 summarize() 計算每組的統計值,例如平均油耗、樣本數等,是進行群組分析的基礎。
資料合併:left_join() /right_join/ inner_join()
當你有兩個資料表(data frames),並想依某個「共通欄位」將它們合併在一起時,dplyr 提供了幾個非常實用的函數來完成這件事,分別是:
left_join()
- 定義: left_join(x, y, by = “key”) 是以左邊的資料表 x 為主,將右邊 y 的資料合併進來。
- 如果 x 中有某筆資料找不到對應的 y,則 y 的欄位會填上 NA。
- 如果 y 中有資料在 x 裡沒對應,會被忽略掉。
- 用途:
這是最常用的 join,因為你想保留主資料集裡的所有資料,只補上來自別的表的資訊。
x <- data.frame(id = 1:3, score = c(85, 90, 95))
y <- data.frame(id = c(2, 3, 4), grade = c("B", "A", "C"))
left_join(x, y, by = "id")
x 所有資料都保留,y 的資訊有對應的才合併進來。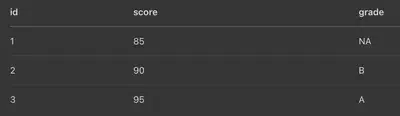
right_join()
- 定義: right_join(x, y, by = “key”) 是以右邊的資料表 y 為主,把 x 合併過去。
- 沒有在 y 裡出現的 key 值會被移除。
- x 裡沒對應的資料會補上 NA。
- 用途: 當你有一個「標準清單」在右邊的資料表,你希望所有清單都保留,而來自左邊的資料是補充用。
right_join(x, y, by = "id")
y 全部保留,x 有對應就補上,沒有就 NA。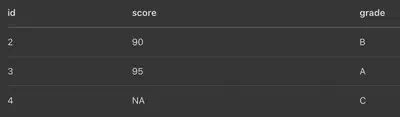
inner_join()
定義: inner_join(x, y, by = “key”) 會
保留兩邊都有對應 key 值的資料,沒有的就捨棄。用途: 當你只關心「兩邊都有資料」的
共同項時,適合使用 inner_join()。
inner_join(x, y, by = "id")
只留下 id = 2 與 id = 3,因為這是兩張表都有的。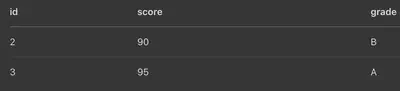
avg_data <- dat |>
group_by(manufacturer) |>
summarize(avg_cty = mean(cty))
joined_data <- left_join(dat, avg_data, by = "manufacturer")
當你擁有兩張資料表時,可以使用 left_join() 或 inner_join() 依照指定欄位合併。這對於將 summary 整併回原始資料非常實用。
管道運算符 |>:提高可讀性與效率
dat |>
filter(manufacturer == "toyota") |>
mutate(avg_mpg = (cty + hwy)/2) |>
arrange(desc(avg_mpg)) |>
select(manufacturer, model, avg_mpg)
使用 |> 可以將多個操作串接起來,依序執行,大幅提高可讀性與維護性。這種寫法對於資料處理流程清晰透明,非常推薦!
建議延伸學習
以下為 dplyr 的延伸工具與套件,適合進階學習:
- purrr:函數式編程,適合對每一行或每一組資料套用自訂邏輯。
- tidyr:資料轉置、整理、reshape 等。
- ggplot2:可與 dplyr 無縫整合,視覺化分群、趨勢與摘要結果。
- modelr / broom:將統計模型的輸出轉為 tidy 格式,方便進一步分析與繪圖。
課程小結
本課程讓你掌握 dplyr 的核心功能,包括資料篩選、選欄、排序、新增欄位、群組統計與合併等常見操作。搭配 pipe 管道運算符可以寫出結構清晰、邏輯分明的資料處理流程。這些技巧是進行資料探索、可視化與建模前的關鍵步驟。